Stacks, Queues, Linked Lists? Got them all under your belt yet having pre-interview jitters?
Relax. Our FAQ guide for interviews on DSA is here to help. We have meticulously gone through interview experiences, have dived deep into our understanding of the subject, and racked the brains of our expert mentors to present to you a definitive guide to cracking those interviews.
However, nothing beats a deep understanding of the concept at hand; a last-minute revision never hurts.
FAQs on Data Structure and Algorithms (DSA)

There can be n number of questions from a vast concept like this, but if we focus on some key points and try to understand the nitty-gritty of the subject, one can very well emerge victorious from the interview room.
We will be clubbing a few questions together to make it easier for a learner to take that last-minute look. Read on.
Data Structure FAQs
- What is Data Structure?
- Goals and usage of Data Structure?
- What are the various Data Structures available?
- What are linear and non-linear DS? What are the common operations that can be performed in DS?
- What are trees in DSM? What are Graphs and their uses? Difference between Data Structure tree and Graphs?
Answers
Let’s get a gist of DS, shall we?
DS is an essential part of any programming language. It is a way to manage and store data so that it can be accessed in a systematic way when needed. It aims to reflect the actual relationship among the data and how efficiently various functions can be applied. It is used to efficiently manage large amounts of data such as various indexing services, artificial intelligence, machine learning, blockchain, etc.
The various types of DS available are Array, Linked Lists, Queues, Stacks, Trees, Graphs, and so on.
Essentially, there are two types of DS:
- Linear DS: if the elements of a DS are in sequence. Common operations that can be performed are Arrays, Stacks, Queues, Linked Lists, etc.
- Non-linear DS: if the elements of a DS are not in sequence and data elements can’t be traversed in a single run. Common operations that can be performed are trees, graphs, etc.
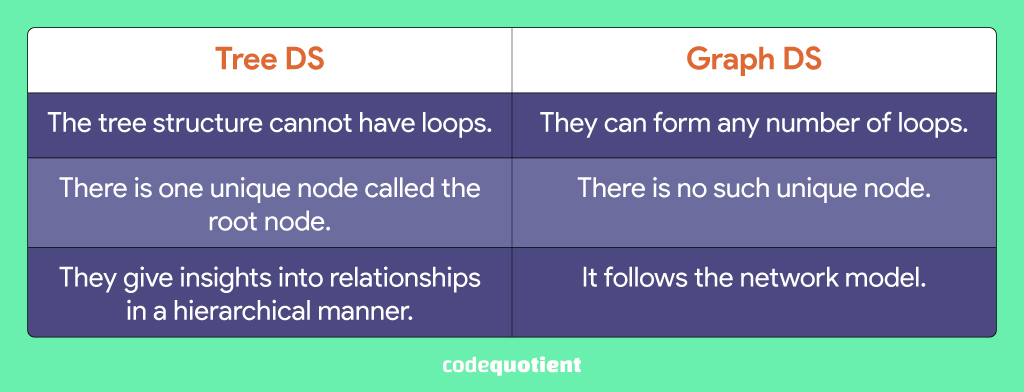
A tree data structure is a non-linear data structure that is hierarchical, and elements are arranged on multiple levels. The topmost node is called the root node, and each subsequent node is called the child of the root. Application of this type of DS can be found in File systems, social media comments, family trees, geological charts, etc.
A Graph in DS is a non-linear data structure made up of vertices/nodes and edges/lines where a pair of vertices are connected by edges, which may be directed or undirected. They are used to denote social networks and the flow of information on sites like Facebook, etc., in services like transport, phone, power grids, etc.
Difference between Tree and Graph Data Structure:
Also read: How to Plan the Future of Work: Work From Home, Office, or Hybrid?
Algorithm FAQs
- What is an Algorithm?
- Why do we need Algorithm Analysis?
- Criteria of Algorithm Analysis?
- What is Asymptotic Analysis of an Algorithm? What are the notations?
- Briefly explain the approaches to developing algorithms?
Answers
Algorithms are a set of step-by-step instructions that are used to solve a problem or accomplish a task. A good example of algorithms can be a recipe that has step-by-step instructions.
Algorithm analysis is important because inefficient algorithms can significantly affect the performance of a program, and an improper algorithm can render results ineffective or corrupt.
Algorithm analysis depends on two factors:
- Space Complexity means the amount of memory an algorithm needs to run its process.
- Time Complexity means the time taken by an algorithm to run its process.
Asymptotic analysis of an algorithm is a method to denote the limiting behaviour of an algorithm. It is an analysis conducted for a large volume of input values where ‘a’ algorithm is considered better than ‘b’ algorithm if the growth of run time of ‘a’ is lower than that of ‘b’, where the value of input can grow any number of times.
There are 3 basic cases corresponding to the efficiency analysis of an algorithm:
- Best case
- Average case
- Worst case
And there are 5 notations to address them:
- Theta notation resembling tightly bound average case efficiency
- Big oh notation resembling tightly bound worst case efficiency
- Omega notation resembling tightly bound best case efficiency
- Little oh notation resembling loosely bound worst case efficiency
- Little omega notation resembling loosely bound best case efficiency
There are 3 commonly used approaches to develop algorithms:
- The greedy approach where we select the next best option to solve a problem.
- Divide and Conquer where problems are broken down into smaller subproblems and then solved individually.
- Dynamic Programming is where problems are broken down into smaller subproblems and solved together.
Array FAQs
- What is Array?
- What is a multidimensional array and a dynamic array?
- What are the characteristics of Array Data Structure?
Answers
An Array is a collection of fixed numbers of similar data points stored at adjoining memory locations and can be accessed randomly just by using its index numbers.
A Multidimensional Array is an array with more than 2 dimensions where each element of the array is associated with multiple indices. They are used to store data for mathematical computation, image processing, and record management.
A Dynamic Array is the type of random access array where the size changes automatically when we insert or delete data together with the memory used during run time.
Some of the characteristics of Array Data Structure are:
- Indices start with 0 and end with -1
- Array name indicates its base address.
- The first element of the Array is the base address.
- Array elements are stored in adjoining memory blocks in the primary memory.
Linked Lists FAQs
- What are Linked Lists?
- What are the different types of Linked Lists?
- Are Linked Lists linear or nonlinear types?
- Are Linked Lists more efficient than Arrays? Why?
- What are Doubly Linked Lists (DLL) and their applications?
Answers
Linked Lists are a chain-like sequence of nodes where every node is connected to the next node with links, i.e. reference pointers. Each node had 2 parts:
- A data field
- A reference pointer to the next node.
A good example can be a music player that has a next or previous feature.
The different types of Linked Lists are:
- Singly Linked list
- Doubly Linked list
- Circular Linked list
- Doubly Circular Linked list
Depending on the application, Linked Lists can be both linear and non-linear data structures. If used to access strategies, it can be considered a linear data structure. If used for data storage, it can be non-linear in nature.
Advantages of Linked Lists over Array:
- It is easier to store data of different sizes in Linked Lists as Array assumes each data to be of the same size.
- Being of dynamic size, resizing Linked Lists is easy compared to Arrays as they are of fixed size.
- Insertions and deletions in Linked Lists don’t shift data, whereas in Array, data is usually shifted.
- Shuffling a Linked List can be done just by changing the pointers, whereas in Array, it is more complicated and takes more memory.
- A Linked List can grow organically, but an Array needs to be recreated when it needs to grow.
Doubly Linked Lists (DLL) are a type of Linked List where a node connects to both the previous node and the next node in sequence allowing data elements to traverse in both directions. Example: the undo and redo button on an Excel page.
Stacks FAQs
- What is Stack?
- What are its applications?
- Why do we use them?
Answers
Stack is a linear data structure where data is stored and retrieved in Last in First out (LIFO) method.
Stacks can be applied in:
- Expression Evaluation
- Expression Conversion
- Backtracking
- Memory management
We use Stack because it is a linear data structure and it allows all data operations to happen at one end only, i.e. only on the top element. (Last in First out, remember?)
Queue FAQs
- What is Queue, and what are its applications?
- Why do we use them?
- What is Dequeue and Enqueue?
- How are stacks different from Queue?
Answers
Queue is a linear data structure where data is stored and retrieved on both ends. It follows a FIFO (First in First out) method. Here one end is used to add data, and the other end is used to remove data.
Queue is used when we need to work on data in an exact sequence of their arrival. As it follows the FIFO method, elements at the beginning get deleted, whereas elements get added at the top.
Dequeue is when we delete data from a Queue. This usually happens at the first element of the data structure, and Enqueue is when we add data to a Queue, and that is usually the last element in the data structure.
The main point of difference between a Stack and a Queue is that data operations happen on the last element only in Stack as it follows LIFO method and in Queue data operations happen on both ends of the data structure as it follows FIFO method.
Also read: Mahak and Her Success Story With CodeQuotient
Cracking interviews is an art. And just like other arts, practice is an integral part. Appearing for mock interviews can be good for practice. The experiences of seniors and mentors should be taken into account. Also, being confident is a must. No one will like an unsure employee. It’s practically not possible to know everything from any given subject. So, being humble and gracious enough with things that you don’t know is a smart choice. This also shows the eagerness to learn. These are some of the personal traits that an interviewee should have.
For everything else related to the subject and proper mentorship, with a focus on project-based learning, do enrol in CodeQuotient’s SuperCoder Program, a free 3-month long online course on ‘full-stack development’ available to anyone who is interested in upskilling themselves or has a basic understanding about coding.
Do check us out and apply now.